Democratizing AI: Building Blocks for Self-Service Solutions
Written on
Chapter 1: AI as a Universal Power Source
The concept of AI has become as essential as electricity in our daily lives. Restricting access to AI and machine learning (ML) solely to specialized teams can impede the competitive edge of various departments like sales, marketing, and customer support. These teams may struggle with outdated tools, leading to inefficiencies. For instance, marketers might make less effective campaign choices, customer support may face difficulties in managing wait times due to inaccurate forecasts, and sales teams could struggle with customer retention and lead generation. This underscores the necessity for democratizing AI across the organization.
In today's landscape, numerous open-source tools and startups are rapidly evolving the AI domain, yet technology leaders often find it challenging to navigate this complex environment. Teams may be lured by the allure of "shiny new technologies" rather than selecting the appropriate foundational elements needed to democratize AI in accordance with their existing processes, technology, data literacy, and skill sets.
This article aims to clarify the technology landscape regarding the user journey from raw data to AI-generated insights. While AI encompasses more than just ML, the two terms are used interchangeably throughout this discussion.
Section 1.1: Understanding the AI Journey Map
The journey of any AI initiative parallels that of any data-driven project. It can be divided into four essential phases: discovery, preparation, building, and operationalizing.
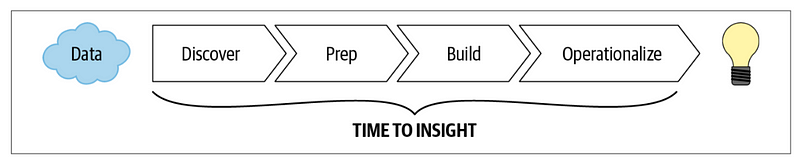
Organizations have recognized the importance of automating and democratizing the AI journey, thus enabling self-service capabilities for both technical and non-technical users. Examples of self-service data and ML platforms include Google’s TensorFlow Extended (TFX), Uber’s Michelangelo, Facebook’s FBLearner Flow, and Airbnb’s Bighead. However, these frameworks are not one-size-fits-all solutions; the optimal choice for an organization hinges on its specific AI/ML use cases, data types, existing technologies, data quality, processes, culture, and skill sets.
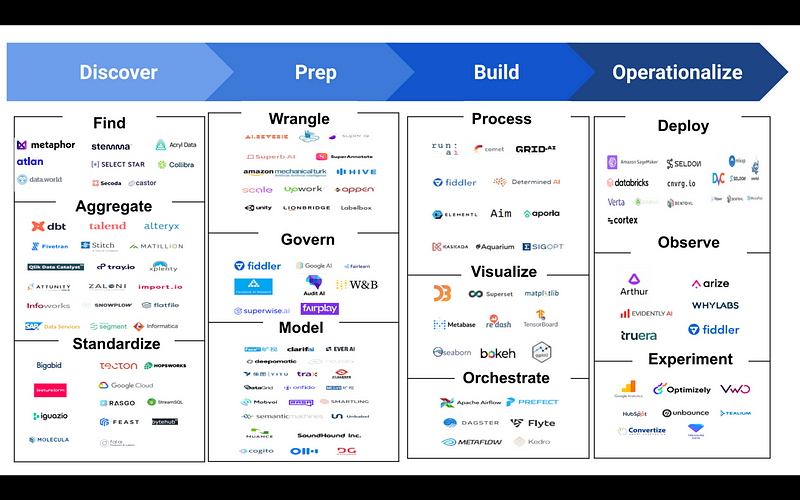
Subsection 1.1.1: Twelve Milestones in the AI Journey
The journey map for an AI project can be broken down into twelve milestones:
- Find: Identify existing datasets and their metadata.
- Aggregate: Collect new structured, semi-structured, or unstructured data from various sources.
- Standardize: Create and reuse standardized features across different ML projects.
- Wrangle/Label: Clean, transform, and label the data for further use.
- Govern: Ensure privacy and fairness in ML models.
- Model: Formulate the ML problem, leveraging pre-built models where applicable.
- Process/Train: Train the models using the prepared datasets.
- Visualize: Analyze and debug models through visualization techniques.
- Orchestrate: Set up comprehensive transformation pipelines from raw data to insights.
- Continuous Deploy: Implement ongoing integration and rollout of models.
- Observe: Monitor for model drift and ensure explainability.
- Experiment: Conduct A/B testing to validate insights and their business impact.
The current AI technology landscape for 2022 is illustrated below, with subsequent sections delving into each of these milestones.
Section 1.2: Discovering Datasets
- Finding Datasets

The journey begins with identifying available datasets and understanding their metadata. This groundwork is crucial for effective data utilization.
- Aggregating Data

Next, organizations must gather new data from various structured and unstructured sources to enhance their datasets.
- Standardizing Features

The use of feature stores is becoming increasingly common as they provide a repository of well-documented, governed, and curated features. This not only streamlines the process of developing ML models but also fosters reuse across projects.